
Research Article
Austin J Clin Cardiolog. 2016; 3(1): 1044.
A Soft Computing Approach to Acute Coronary Syndrome Risk Evaluation
Vicente H1,2, Martins MR3, Mendes T1, Vilhena J1, Gra&nTilde;eda JM4, Gusm&aTilde;o R4 and Neves J2*
¹Departamento de Química, Escola de Ciências e Tecnologia, Universidade de Évora, Portugal
²Departamento de Informatica, Universidade do Minho, Portugal
³Departamento de Química, Escola de Ciências e Tecnologia, Laboratório Hercules, Universidade de Évora, Portugal
4Serviço de Patologia Clínica do Hospital do Espírito Santo de Évora EPE, Portugal
*Corresponding author: Jose Neves, Departamento de Informatica, Universidade do Minho, Portugal
Received: December 15, 2015; Accepted: May 16, 2016; Published: May 18, 2016
Abstract
Acute Coronary Syndrome (ACS) is transversal to a broad and heterogeneous set of human beings, and assumed as a serious diagnosis and risk stratification problem. Although one may be faced with or had at his disposition different tools as biomarkers for the diagnosis and prognosis of ACS, they have to be previously evaluated and validated in different scenarios and patient cohorts. Besides ensuring that a diagnosis is correct, attention should also be directed to ensure that therapies are either correctly or safely applied. Indeed, this work will focus on the development of a diagnosis decision support system in terms of its knowledge representation and reasoning mechanisms, given here in terms of a formal framework based on Logic Programming, complemented with a problem solving methodology to computing anchored on Artificial Neural Networks. On the one hand it caters for the evaluation of ACS predisposing risk and the respective Degree-of-Confidence that one has on such a happening. On the other hand it may be seen as a major development on the Multi-Value Logics to understand things and ones behavior. Undeniably, the proposed model allows for an improvement of the diagnosis process, classifying properly the patients that presented the pathology (sensitivity ranging from 89.7% to 90.9%) as well as classifying the absence of ACS (specificity ranging from 88.4% to 90.2%).
Keywords: Artificial neuronal networks; Acute coronary syndrome; Acute myocardial infarction; Cardiovascular disease risk assessment; Knowledge representation and reasoning; Logic programming
Abbreviations
ACS: Acute Coronary Syndrome; AMI: Acute Myocardial Infarction; ANNs: Artificial Neural Networks; AUC: Area Under the Curve; BMI: Body Mass Index; CK-MB: Creatine Kinase MB; cTnI: cardiac Troponin I; DoC: Degree-of-Confidence; ECG: Electrocardiogram; ELP: Extended Logic Program; FN: False Negative; FP: False Positive; HESE: Hospital do Espírito Santo de Évora; HRP: Horseradish Peroxidase; LP: Logic Programming; LSH: Life Style Habits; NPV: Negative Predictive Value; NSTE: Non-ST-segment Elevation; NSTEMI: Non-ST-segment Elevation Myocardial Infarction; PPV: Positive Predictive Value; QoI: Qualityof- Information; RCM: Related Clinic Manifestations; ROC: Receiver Operating Characteristic; STE: ST-segment Elevation; STEMI-ST: segment Elevation Myocardial Infarction; TN: True Negative; TP: True Positive
Introduction
The Acute Coronary Syndrome (ACS) stands for a complex and serious medical disorder that is presented in any group of individuals that appear to have clinical symptoms compatible with acute myocardial ischemia, including unstable angina, Non-STsegment Elevation Myocardial Infarction (NSTEMI) and ST-segment Elevation Myocardial Infarction (STEMI). These high-risk coronary manifestations are associated with high mortality and morbidity, with heterogeneous etiology, characterized by an imbalance between the requirement and the availability of oxygen in the myocardium [1].
In Europe, cardiovascular diseases are responsible for more than 2 million deaths per year, representing about 50% of all deaths, and for 23% of the morbidity cases [2,3]. This may be related to factors associated with the processes of industrialization going on in many countries, therefore affecting lifestyles and sedentary, which associated with a less healthy diet sometimes based on processed foods, may contribute to the prevalence of hypertension and increase the serum levels of cholesterol and glucose.
Despite modern treatment the amounts of deaths due to Acute Myocardial Infarction (AMI) and readmission of patients with ACS remain high [2,4]. Patients with chest pain represent a very substantial proportion of all acute medical hospitalization in Europe. Under a thorough medical profile indicative of ischemia, the Electrocardiogram (ECG) is a priority after hospital admission. The patients are often grouped in two categories, namely patients with acute chest pain and persistent ST-segment Elevation (STE), and patients with acute chest pain but without persistent ST-segment elevation, i.e., Non-ST-segment Elevation (NSTE) [3,4]. Besides the higher hospital mortality in STE-ACS patients, the annual incidence of NSTE-ACS patients is higher than STE-ACS ones [5,6]. Furthermore, a long-term follow-up showed the increase of death rates in NSTEACS patients, with more co-morbidity, mainly diabetes mellitus, chronic renal diseases and anemia [2,7]. Premature mortality is increased in individuals susceptible to accelerated atherogenesis caused by accumulation of others risk factors, namely age over 65 years, hypertension, obesity, lipid disorders and tobacco habits. Some studies reported an association of incidence of coronary artery disease and recurrent AMI with the presence of persistently increased titers of anti PhosphoLipid antibodies, such as anti Cardiolipin antibodies, lupus anticoagulant and anti-β2 GlycoProtein I [8].
The diagnosis of ACS relies, besides the clinical symptoms and ECG findings, primarily on biomarker levels [9,10]. Markers of myocardial necrosis such as cardiac troponins (I or T), the isoenzyme of Creatine Kinase MB (CK-MB), of which the primary source is the myocardium, and myoglobin reflect different pathophysiological aspects of necrosis, and are the gold standard in detection of ACS [9,11]. According to the European Society of Cardiology, troponins (I, T) have high sensibility to the myocardial cellular damage and play a central role in the diagnosis process, establishing and stratifying risk and making possible to distinguish between NSTEMI and unstable angina [2,12]. Nevertheless, CK-MB is useful in association with cardiac troponin in order to discard false positives diagnosis, namely in pulmonary embolism, renal failure and inflammatory diseases, such as myocarditis or pericarditis [12,13].
Solving problems related to ACS risk requires a proactive strategy. However, the stated above shows that the ACS assessment should be correlated with many variables and requires a multidisciplinary approach. Thus, it is difficult to assess to the ACS since it needs to consider different conditions with intricate relations among them, where the available data may be incomplete, contradictory and/ or unknown. This work is focused on the development of a hybrid methodology for problem solving, aiming at the elaboration of a clinical decision support systems to predict ACS risk, according to a historical dataset, that associates Logic Programming (LP) based approach (to knowledge representation and reasoning [14,15], and a computational framework based on Artificial Neural Networks (ANNs) [16,17]. ANNs were selected due to their dynamics characteristics like adaptability, robustness and flexibility. Indeed, this approach goes in depth in aspects like the attribute’s Quality-of- Information (QoI) [18] and Degree-of-Confidence (DoC) [19,20], which makes possible the handling of unknown, incomplete or even contradictory data or knowledge.
Materials and Methods
Study protocol
The patients were screened in the Emergency Department of the Hospital do Espírito Santo de Évora (HESE), Portugal, and followed up in the Laboratory of Clinical Pathology of this healthcare unit, with the quantification of cardiac biomarkers. The study protocol was approved by the Ethics Committee of HESE. Demographic data, clinical history, complementary diagnostic tests and the final diagnosis were obtained by accessing the HESE Information System. Patients were undergoing fasting and blood was sampling without tourniquet to prevent the haemolysis, platelet aggregation and tissue factor release [21]. Plasma specimens were performed using lithium heparin or sodium citrate as anticoagulant. All samples obtained were centrifuged at 2000g for 15 minutes at room temperature and the plasma was separated for analysis.
Measurement of cardiac biomarkers
The quantitative measurement of cardiac Troponin I (cTnI), the isoenzime creatinine cinase CK-MB and Myoglobin in human serum and plasma (heparin and EDTA) was performed by chemiluminescent assay using an automatized VITROS 5600® (Ortho Clinical Diagnostics). For the evaluation of cTnI, CK-MB or Myoblobin an immunometric immunoassay technique is used, which involves the simultaneous reaction of cTnI, CK-MB, Myoglobin present in the sample with the specific mouse monoclonal biotinylated antibody and a Horseradish Peroxidase (HRP) - labeled antibody conjugate. The bound HRP conjugate is measured by a luminescent reaction. The HRP in the bound conjugate catalyzes the oxidation of the luminol derivative, producing light. The electron transfer agent (a substituted acetanilide) increases the level of light produced and prolongs its emission. The light signals are read by the system. The amount of HRP conjugate bound is directly proportional to the concentration of cTnI, CK-MB or Myoblobin present.
Knowledge representation and reasoning
In several situations it is necessary to handle with estimated values, probabilistic measures, or degrees of uncertainty. In other words, the decisors are often faced with information with some degree of incompleteness, nebulousness and even contradictoriness. The notion of uncertainty is broader than error or accuracy and includes these more restricted concepts. The accuracy concept is related with the closeness of measurements or computations to their “true” value (or a value held as “truth”), while the uncertainty can be considered as any aspect of the data that results in less than perfect knowledge about the phenomena being studied [22]. Furthermore, knowledge and belief are generally incomplete, contradictory, or even error sensitive, being desirable to use formal tools to deal with the problems that arise from the use of partial, contradictory, ambiguous, imperfect, nebulous, or missing information [15,22]. Some non-classical techniques have been presented where uncertainty is associated to the application of Probability Theory [23], Fuzzy Set Theory [24], or Similarities [25]. Other approaches for knowledge representation and reasoning have been proposed using the Logic Programming (LP) paradigm, namely in the area of Model Theory [26,27] and Proof Theory [14,15]. The proof theoretical approach, in terms of an extension to the LP language to knowledge representation and reasoning is followed in the present work. An Extended Logic Program (ELP) is a finite set of clauses in the form:
{p ← p1,..., pn, not q1,..., not qm? (p1,..., pn, not q1,..., not qm) (n, m= 0) exceptionp1... exceptionpj (j = m,n)} :: scoringvalue
Where “?” is a domain atom denoting falsity, the pi, qj, and p are classical ground literals, i.e., either positive atoms or atoms preceeded by the classical negation sign ¬ [14]. Under this formalism, every program is associated with a set of abducibles [26,27], given here in the form of exceptions to the extensions of the predicates that make the program. The term scoringvalue stands for the relative weight of the extension of a specific predicate with respect to the extensions of the peers ones that make the overall program. The objective is to build a quantification process of QoI and DoC [18-20]. The Qualityof- Information (QoIi) with respect to the extension of a predicatei will be given by a truth-value in the interval [0, 1]. Thus, QoIi = 1 when the information is known (positive) or false (negative) and QoIi = 0 if the information is unknown. Finally for situations where the extension of predicatei is unknown but can be taken from a set of terms, the QoIi ∈ [0, 1] [18]. DoCi stands for an assessment of attributei with respect to the terms that make the extension of predicatei, i.e., it denotes a measure of one’s confidence that the attribute value fits into a given interval, whose boundaries are evaluated in a way that takes into consideration its domain [19].
Therefore, the universe of discourse is engendered according to the information presented in the extensions of a given set of predicates, according to productions of the type:
Where U and m stand, respectively, for set union and the cardinality of the extension of predicatei.
Artificial neural networks
ANNs are computational tools which attempt to simulate the architecture and internal operational features of the human brain and nervous system. ANNs can be defined as a connected structure of basic computation units, called artificial neurons or nodes, with learning capabilities. Multilayer perceptron is the most popular ANN architecture, where neurons are grouped in layers and only forward connections exist, often used for prediction as well as for classification. Indeed, this provides a powerful base-learner, with advantages such as nonlinear mapping and noise tolerance, increasingly used in Data Mining due to its good behavior in terms of predictive knowledge [17].
In order to ensure statistical significance of the attained results, 30 (thirty) experiments were applied in all tests. In each simulation, the available data was randomly divided into two mutually exclusive partitions, i.e., the training set with 67% of the available data, used during the modeling phase, and the test set with the remaining data (i.e., 33%) used after training in order to evaluate the model performance and to validate it. The back propagation algorithm was used in the learning process of the ANN. As the output function in the pre-processing layer the identity one was used. In the other layers we used the sigmoid function.
Assessment of cardiac biomarkers and models
The performance assessment of each cardiac biomarker and model is carried out based on the coincidence matrix, created by matching the predicted and target values Table 1. Based on coincidence matrix it is possible to compute sensitivity, specificity, Positive Predictive Value (PPV) and Negative Predictive Value (NPV) of the classifier:
![]()
Target
Predictive
True (1)
False (0)
True (1)
True Positive
False Negative
False (0)
False Positive
True Negative
Table 1: A Generic Coincidence Matrix.
Sensitivity = TP / (TP + FN) (2)
Specificity = TN / (TN + FP) (3)
PPV = TP / (TP + FP) (4)
NPV = TN / (TN + FN) (5)
Where TP, FP, FN and TN stand for True Positives, False Positives, False Negatives and True Negatives, respectively.
The sensitivity and specificity are statistical measures of the performance of a binary classifier. Sensitivity measures the proportion of true positives that are correctly identified as such, while specificity measures the proportion of true negatives that are also correctly identified. Moreover, it is necessary to know the probability of the classifier that gives the correct diagnosis. Thus, it is also calculated both PPV and NPV, while PPV stands for the proportion of cases with positive values that were correctly diagnosed, NPV denotes the proportion of cases with negative values that were successfully labeled [28].
In addition, the Receiver Operating Characteristic (ROC) curves were considered. An ROC curve displays the trade-off between sensitivity and specificity and may be used to visualize the performance of a binary classifier, i.e., a classifier (a cardiac biomarker or a model in this case) with two possible output classes (i.e., two patient states referred as diseased and non-diseased). The Area Under the Curve (AUC) quantifies the overall ability of the test to discriminate between the output classes. The AUC can be interpreted as the probability that a randomly chosen diseased subject is rated or ranked as more likely to be diseased than a randomly chosen non-diseased subject [29]. The maximum AUC, i.e., 1 (one) means that the test is perfect in the differentiation between the two possible output classes. This happens when the distribution of test results for the output classes do not overlap. The minimum AUC should be considered a chance level, i.e., AUC = 0.5, since AUC = 0 means that the test classifies incorrectly all subjects.
Results
Sample characterization
The general characteristics of the patient screening in the Emergency Department of the HESE and followed up in the Laboratory of Clinical Pathology of this healthcare unit are presented in Table 2. A perusal of Table 2 revealed a low percentage of patients with ACS (i.e., 6.7%). The incidence of the pathology was higher in male (64.7%) than female patients (35.3%). Moreover, 40.5% of patients with ACS showed chest pain, 18.1% revealed a previous myocardium infarction and 45.7% are hypertensive. Regarding the patients without ACS, 25.5%, 6.3% and 26.8% showed chest pain, a previous myocardium infarction and hypertension, respectively. The population was divided into three age groups for the evaluation of biomarkers performance [7]. The age group where there was a greater incidence of SCA was the one that includes patients older than 65 (72.4%). Results are in accordance with other studies that showed high incidence for patients older than 65 years [2,3].
![]()
Patients with ACS
116 (6.7)
Patients without ACS
1626 (93.3)
Male
75 (64.7)
806 (49.6)
Female
41 (35.3)
820 (50.4)
Age (years old)
[35, 50[
8 (6.9)
132 (8.1)
[50, 65]
24 (20.7 )
302 (18.6)
> 65
84 (72.4)
1192 (73.3)
cTnI (ng/cm3)
< 0.03
27 (23.3)
1132 (69.6)
= 0.03
89 (76.7)
494 (30.4)
CK-MB (ng/cm3)
< 2.4
58 (50.0)
1298 (79.8)
= 2.4
58 (50.0)
328 (20.2)
Myoglobin (ng/cm3)
< 25
69 (59.5)
1149 (70.7)
= 25
47 (40.5)
477 (29.3)
History
Chest pain
47 (40.5)
415 (25.5)
Previous myocardium infarction
21 (18.1)
102 (6.3)
Hypertension
53 (45.7)
435 (26.8)
Smoking habits
16 (13.8)
87 (5.4)
Obesity
11 (9.5)
109 (6.5)
Lipid disorders
23 (18.8)
312 (19.2)
Diabetes mellitus
33 (28.4)
335 (20.6)
Chronic Renal Disease
5 (4.3)
96 (5.9)
Note: Values stand for number of patients (in percentage)
Abbreviations: ACS - Acute Coronary Syndrome; CK-MB - Creatine Kinase MB; cTnI - cardiac Troponin I
Table 2: General Characteristics of the Patients in Study (n=1742).
Evaluation of performance of cardiac biomarkers
In order to evaluate the performance of cardiac biomarkers the counting of True Positives (TP), False Positives (FP), False Negatives (FN) and True Negatives (TN) was made. A TP is a patient diagnosed as diseased and with a value of the cardiac biomarker higher than the threshold (i.e., 0.03 ng/cm3, 2.4 ng/cm3 and 25 ng/cm3 for cTnI, CK-MB and Myoglobin, respectively) [2,9,10], while a FP is a patient diagnosed as non-diseased and exhibits a value of the cardiac biomarker higher than the threshold. Conversely, a FN is a patient diagnosed as diseased and with a value of the cardiac biomarker lower than the cutoff value, whereas a TN is a non-diseased one with a value of the cardiac biomarker lower than the cutoff value. The results are displayed in Table 3.
![]()
Target
Predictive
cTnI
CK-MB
Myoglobin
True (1)
False (0)
True (1)
False (0)
True (1)
False (0)
All Ages
True (1)
TP = 89
FN = 27
TP = 58
FN = 58
TP = 47
FN = 69
False (0)
FP = 494
TN = 1132
FP = 328
TN = 1298
FP = 477
TN = 1149
Age
�[35, 50]
True (1)
TP = 7
FN = 1
TP = 4
FN = 4
TP = 3
FN = 5
False (0)
FP = 26
TN = 106
FP = 15
TN = 117
FP = 23
TN = 109
Age
[50, 65]
True (1)
TP = 17
FN = 7
TP = 10
FN = 14
TP = 8
FN = 16
False (0)
FP = 53
TN = 249
FP = 47
TN = 255
FP = 54
TN = 248
Age > 65 years old
True (1)
TP = 65
FN = 19
TP = 44
FN = 40
TP = 36
FN = 48
False (0)
FP = 415
TN = 777
FP = 266
TN = 926
FP = 400
TN = 792
Abbreviations: CK-MB - Creatine Kinase MB; cTnI - cardiac Troponin I; FN - False Negative; FP - False Positive; TN - True Negative; TP - True Positive
Table 3: The Coincidence Matrix for Cardiac Biomarkers.
Based on coincidence matrix it is possible to compute sensitivity, specificity, Positive Predictive Value (PPV) and Negative Predictive Value (NPV) of each cardiac biomarker. The corresponding sensitivity, specificity, PPV and NPV values are showed in Table 4 for cardiac biomarkers, i.e., cTnI, CK-MB and myoglobin. A perusal of Table 4 shows that the cTnI presents the higher values of sensitivity, PPV and NPV, while CK-MB exhibits the higher specificity value. Conversely, myoglobin presents the lower values of sensitivity, PPV and NPV, while cTnI exhibits the lower specificity value.
![]()
Sensitivity (%)
Specificity (%)
PPV (%)
NPV (%)
All Ages
cTnI
76.7
69.6
15.3
97.7
CK-MB
50.0
79.8
15.0
95.7
Myoglobin
40.5
70.7
9.0
94.3
Age
[35, 50[
cTnI
87.5
80.3
21.2
99.1
CK-MB
50.0
88.6
21.1
96.7
Myoglobin
37.5
82.6
11.5
95.6
Age
[50, 65]
cTnI
70.8
82.5
24.3
97.3
CK-MB
41.7
84.4
17.5
94.8
Myoglobin
33.3
82.1
12.9
93.9
Age> 65 years old
cTnI
77.4
65.2
13.5
97.6
CK-MB
52.4
77.7
14.2
95.9
Myoglobin
42.9
66.4
8.3
94.3
Abbreviations: CK-MB - Creatine Kinase MB; cTnI - cardiac Troponin I
Table 4: Sensitivity, Specificity, Positive Predictive Value (PPV) and Negative Predictive Value (NPV) for the Cardiac Biomarkers.
A logic programming data assessment
Aiming to develop a diagnosis decision support system in order to evaluate the risk of ACS, let us consider the knowledge base given in terms of the extensions of the relations (or tables) depicted in Figure 1, which stands for a situation where one has to manage information about ACS. The knowledge base includes features obtained by both objective and subjective methods, i.e., the physicians may populate some issues while executing the health check. Others may be perceived by laboratorial tests (e.g., this happens with the issues of the Cardiac Biomarkers or ECG tables). Under this scenario some incomplete and/or unknown data is also present. For instance, for patient 1 the information regarding Heredity is unknown, which is represented by the symbol ⊥, while the Related Clinical Manifestations range in the interval [3,4].
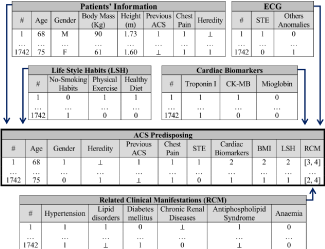
Figure 1: A fragment of the knowledge base for Acute Coronary Syndrome Risk Evaluation.
The issues of ECG and Related Clinical Manifestations tables, the columns Physical Exercise and Healthy Diet of Life Style Habits table and the columns Previous ACS, Chest Pain and Heredity of Patient’s Information table are filled with 0 (zero) or 1 (one) denoting, respectively, no or yes. In Cardiac Biomarkers table 0 (zero) and 1 (one) stand, respectively, for negative or positive test. The column Smoking Habits of the Life Style Habits table is populated with 0 (zero), 1 (one) or 2 (two), denoting Current Smoker, Ex-Smoker and Never Smoked, respectively. The values presented in the STE, Cardiac Biomarkers, LSH and RCM columns of ACS Predisposing table are the sum of the correspondent tables, ranging between [0, 2], [0, 3], [0, 4] and [0, 6] respectively. The domain of Body Mass Index (BMI) column is in the range [0, 2], wherein 0 (zero) denotes BMI < 25; 1 (one) stands for a BMI ranging in interval [25, 30]; and 2 (two) denotes a BMI = 30. The BMI was evaluated using the equation
BMI = Body Mass / Height2 [30],
While in the Gender column 0 (zero) and 1 (one) stand, respectively, for female (F) and male (M).
Applying the algorithm presented in [31], to all the fields that make the knowledge base for ACS predisposing (Figure 1) and looking to the DoCs values obtained in this manner, it is possible to set the arguments of the predicate referred to below, that also denotes the objective function with respect to the problem under analyze.
acspredisposing : Age, Gender, Heredity, Previous ACS, Chest Pain, ECG, Cardiac Biomakers, Body Mass Index, Life Style Habits, Related Clinical Manifestations → {0,1}
where 0 (zero) and 1 (one) denote, respectively, the truth values false and true.
Exemplifying the application of the algorithm presented in [31], to the patient that presents feature vector (77, 1, 1, 0, ⊥, 1, 1, 1, [0, 2], [2, 4]), one may get:
Begin,
The predicate’s extension that maps the Universe-of-Discourse for the term under observation is set ←
The attribute’s values ranges are rewritten ←
The attribute’s boundaries are set to the interval [0, 1] ←
The DoC’s values are evaluated ←
End.
The DoC is evaluated as it is illustrated in Figure 2, i.e., DoC = 1- Δl2 . Here stands for the argument interval length, which was set in the interval [0, 1].
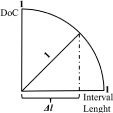
Figure 2: Evaluation of the Degree of Confidence.
Soft computing approach
The model to evaluate ACS predisposing risk presented previously demonstrates how all the information comes together and how it is processed. In this section, a soft computing approach to deal with the processed information is considered. Thus, a hybrid approach was set to model the universe of discourse, based on Artificial Neural Networks (ANNs), which are used to structure data and capture complex relationships between inputs and outputs [32-34]. ANNs simulate the structure of the human brain, being populated by multiple layers of neurons, with a valuable set of activation functions. As an example, let us consider the case given above, where one may have a situation in which the ACS diagnosis is needed. In Figure 3 it is shown how the normalized values of the attributes intervals boundaries and their DoC and QoI values work as inputs to the ANN. The output depicts the ACS predisposing risk, plus the confidence that one has on such a happening. In this study 1742 patients were considered. The ACS was diagnosed in 116 cases, i.e., in 6.7% of the analysed population Table 2. The coincidence matrix of the ANN model, where the values displayed denote the average of 30 experiments is present in Table 5. A glance of Table 5 shows that the model accuracy was 90.3% for the training set (1048 correctly classified in 1161) and 88.5% for test set (513 correctly classified in 581). Thus, the predictions made by the ANN model are satisfactory, attaining accuracies close to 90%. Based on coincidence matrix the values of sensitivity, specificity, PPV and NPV of the ANN model were computed for training and test sets Table 6. A perusal of Table 6 shows that the sensitivity ranges from 89.7% to 90.9%, while the specificity ranges from 88.4% to 90.2%.
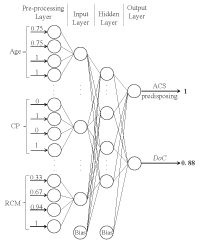
Figure 3: The Artificial Neural Network Topology.
![]()
Target
Predictive
Training set
Test set
True (1)
False (0)
True (1)
False (0)
True (1)
TP = 70
FN = 7
TP = 34
FN = 5
False (0)
FP = 106
TN = 978
FP = 63
TN = 479
Abbreviations: FN - False Negative; FP - False Positive; TN - True Negative; TP - True Positive
Table 5: The Coincidence Matrix for ANN Model.
![]()
Sensitivity (%)
Specificity (%)
PPV (%)
NPV (%)
Training set
90.9
90.2
39.8
99.3
Test set
89.7
88.4
35.7
99.2
Abbreviations: PPV - Positive Predictive Value; NPV - Negative Predictive Value
Table 6: Sensitivity, specificity, PPV and NPV for the ANN model.
Discussion
Concerning the performance of cardiac biomarkers Table 4, the high sensitivity observed for cTnI (76.7%) and the high specificity observed for CK-MB (69.6%) can be related to the nature of such serum cardiac markers. Indeed, cTnI is an isoenzyme of Troponin I associated with fast-twitch cardiac muscle. Clinical studies have demonstrated that cTnI is detectable in the bloodstream 4-6 hours after an Acute Myocardial Infarction (AMI) and remains elevated for several days thereafter [35,36]. Further studies have indicated that cTnI has a higher clinical specificity for myocardial injury than does CK-MB [37]. Because of its cardiac specificity and sensitivity, cTnI has been used as a reliable marker in evaluating patients with unstable angina and NSTE-ACS [3,13]. Creatine kinase is a key enzyme of energy metabolism in muscle, catalyzing the reversible phosphorylation of creatine. The isoenzyme of creatine kinase found predominantly in cardiac muscle (i.e., CK-MB), presents low concentration in normal serum and non-cardiac tissues, whereby is the basis of its widely accepted use as a diagnostic indicator of myocardial injury [9]. Damage to the myocardium results in a transient release of CK-MB into the circulation, reaching a peak in 12 to 24 hours, crucial in the diagnostic of AMI. According to [9] about 98% of patients with AMI exhibit elevated serum CK-MB while only 3% of non-AMI patients exhibit abnormal CK-MB. Myoglobin shows lower specificity than the other markers. Myoglobin is the primary oxygen-carrying pigment of muscle tissue and is high when muscle tissue is damaged but it lacks specificity. This biomarker has the advantage of responding very rapidly, rising and falling earlier than CK-MB or troponin [10,11]. The performance of cardiac biomarkers based on the three age groups is similar to the observed for the whole population. Nevertheless, the sensitivity of biomarkers increases for the age group older than 65, which can be correlated with the high incidence of SCA observed for this age group. The specificity of all cardiac biomarkers is lower for this group as compared to the group between 35…50 years and also the 50… 65 one. The ROC curves for each cardiac biomarker are shown in Figure 4 and the AUC are presented in Table 7. The AUC, ranging between 0.556 and 0.732, are in concordance with the results of sensibility and specificity of biomarkers Table 4, since the cTnI exhibits the higher value of AUC and myoglobin presents the lower one. It denotes that the ability of the cardiac biomarkers to discriminate between diseased and nondiseased states is not very high, and should be complemented with other clinical information in order to conduce to a more effective diagnosis.
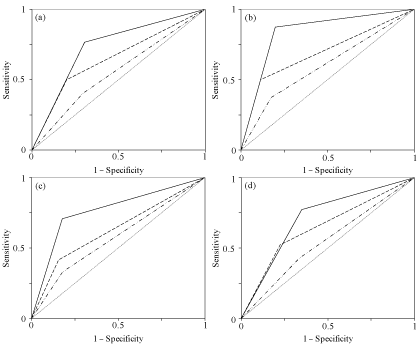
Figure 4: The ROC curves for cardiac biomarkers cTnI (?), CK-MB (− −) and
Myoglobin (−··−) considering
(a) All ages, (b) Age ∈ [35, 50], (c) Age∈[50, 65] and (d) Age > 65 years old.
![]()
All Ages
Age
[35, 50[
Age
[50, 65]
Age > 65 years old
cTnI
0.732
0.839
0.766
0.713
CK-MB
0.649
0.693
0.631
0.650
Myoglobin
0.556
0.600
0.577
0.547
Abbreviations: CK-MB - Creatine Kinase MB; cTnI - cardiac Troponin I
Table 7: Areas under ROC Curves for the Cardiac Biomarkers.
Regarding the proposed ANN model, the sensitivity and specificity Table 6 are higher than the reported above for the cardiac biomarkers Table 4. The PPV ranges from 35.7% to 39.8% indicating that the proportion of cases labeled as diseased that were correctly classified obtained is not very high, and can be attributed to the low incidence of the disease in the cohort. Nevertheless, it is much higher than PPV values found for cardiac biomarkers. Finally, NPV ranges from 99.2% to 99.3% and are close to the values obtained for cardiac biomarkers. The ROC curves for the training and test sets are shown in Figure 5. The areas under ROC curves are higher than 0.9 for both cases, denoting that the model exhibits a good performance in recognition of ACS predisposing risk. The present model allows for the integration of the results of the cardiac biomarkers with other features such as heredity, previous ACS, ECG, life style habits and related clinical manifestations, allowing to be assertive in the diagnosis of ACS. This model showed a high sensibility, enabling the diagnosis of ACS comparing with the patients that really presented this pathology as well as classifying properly the absence of ACS (i.e., specificity). Thus it may be a major contribution to the early recognition and prevention of ACS.
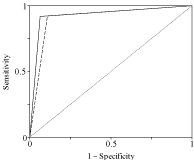
Figure 5: The ROC curves for training set (?) and for test set (- -).
Conclusion
The diagnosis, decision support system presented in this study is able to give an adequate response to the need for a good method of ACS predisposing risk assessment. To go around the problem more effectively, other variables must be studied and considered, thus fulfilling important gaps in the existent risk assessment methods. Being an area filled with incomplete and unknown data it may be tackled by Artificial Intelligence based methodologies and techniques for problem solving. This work presents the founding of a computational framework that uses the powerful knowledge representation and reasoning techniques to set the structure of the information and the associate inference mechanisms. The knowledge representation and reasoning techniques presented above are very versatile and capable of covering almost every possible instance of the problem, namely by considering incomplete, contradictory, and even unknown data or knowledge, a marker that is not present in existing systems. Indeed, this method brings a new approach that can revolutionize prediction tools in all its variants, making it more complete than the existing methodologies and tools available. The model presented in this study showed a good performance in the detection of ACS predisposing, since their sensitivity and specificity exhibited values near 90%. These findings were corroborated by the area under ROC curves (> 0.9). This approach beyond allowing to obtain the ACS predisposing risk also lets us estimate the degree of confidence associated with this diagnosis (88.0% for the example presented above). Indeed, this is one of the added values of this approach, once it combines a framework based on Logic Programming to knowledge representation and reasoning, with a view to computing grounded on ANNs. Indeed, this approach encapsulates in itself a new vision to Multi-Value Logics, because once a proof of a theorem has been accomplished, it presents a measure of the confidence that the computational system has on such a proof.
References
- Allender S, Peto V, Scarborough P, Kaur A, Rayner M. Coronary Heart Disease Statistics. 16th Edn. Oxford: British Heart Foundation. 2008.
- Steg PG, James SK, Atar D, Badano LP, Blomstrom-Lundqvist C, Borger MA, et al. ESC guidelines for the management of acute myocardial infarction in patients presenting with ST-segment elevation. Eur Heart J. 2012; 33: 2569-2619.
- Roffi M, Patrono C, Collet J-P, Mueller C, Valgimigli M, Andreotti F, et al. 2015 ESC guidelines for the management of acute coronary syndromes in patients presenting without persistent ST-segment elevation. Eur Heart J. 2015; 37: 267-315.
- Brogan RA, Malkin CJ, Batin PD, Simms AD, McLenachan JM, Gale CP. Risk stratification for ST segment elevation myocardial infarction in the era of primary percutaneous coronary intervention. World J Cardiol. 2014; 6: 865-873.
- Fox KA, Eagle KA, Gore JM, Steg PG, Anderson FA; GRACE and GRACE2 Investigators. The Global Registry of Acute Coronary Events, 1999 to 2009--GRACE. Heart. 2010; 96: 1095-1101.
- Terkelsen CJ, Lassen JF, Norgaard BL, Gerdes JC, Jensen T, Gotzsche LB, et al. Mortality rates in patients with ST-elevation vs. non-ST-elevation acute myocardial infarction: observations from an unselected cohort. Eur Heart J. 2005; 26: 18-26.
- Anderson JL, Adams CD, Antman EM, Bridges CR, Califf RM, Casey-Jr, DE, et al. ACC/AHA 2007 Guidelines for the Management of Patients With Unstable Angina/Non-ST-Elevation Myocardial Infarction: Executive Summary. Circulation. 2007; 116: 803-877.
- Cooper R, Cutler J, Desvigne-Nickens P, Fortmann SP, Friedman L, Havlik R, et al. Trends and disparities in coronary heart disease, stroke, and other cardiovascular diseases in the United States: findings of the national conference on cardiovascular disease prevention. Circulation. 2000; 102: 3137-3147.
- Antman E, Bassand J-P, Klein W, Ohman M, Sendon JLL, Rydén L, et al. Myocardial infarction redefined - A consensus document of The Joint European Society of Cardiology/American College of Cardiology Committee for the redefinition of myocardial infarction. Eur Heart J. 2000; 21: 1502-1513.
- Hollander JE. The Future of Cardiac Biomarkers, new concepts and emerging technologies for emergency physicians. EMCREG International. 2005; 4: 1-7.
- Mueller C. Biomarkers and acute coronary syndromes: an update. Eur Heart J. 2014; 35: 552-556.
- Thygesen K, Mair J, Katus H, Plebani M, Venge P, Collinson P, Lindahl B. Recommendations for the use of cardiac troponin measurement in acute cardiac care. Eur Heart J. 2010; 31: 2197-2204.
- Agewall S, Giannitsis E, Jernberg T, Katus H. Troponin elevation in coronary vs. non-coronary disease. Eur Heart J. 2011; 32: 404-411.
- Neves J. A logic interpreter to handle time and negation in logic databases. Muller R, Pottmyer J, editors. In: Proceedings of the 1984 Annual Conference of the ACM on the 5th Generation Challenge. Association for Computing Machinery. 1984; 50-54.
- Neves J, Machado J, Analide C, Abelha A, Brito L. The halt condition in genetic programming. Neves J, Santos MF, Machado J, editors. In: Progress in Artificial Intelligence, Lecture Notes in Artificial Intelligence 4874. Springer. 2007; 160-169.
- Cortez P, Rocha M, Neves J. Evolving Time Series Forecasting ARMA Models. J Heuristic. 2004; 10: 415-429.
- Haykin S. Neural Networks and Learning Machines. 3rd edition. New York: Prentice Hall. 2008.
- Machado J, Abelha A, Novais P, Neves J. Quality of service in healthcare units. Bertelle C, Ayesh A, editors. In: Proceedings of the ESM 2008. Eurosis - ETI Publication. 2008; 291-298.
- Cardoso L, Marins F, Magalh&aTilde;es R, Marins N, Oliveira T, Vicente H, et al. Abstract Computation in Schizophrenia Detection through Artificial Neural Network based Systems. The Scientific World Journal. 2015.
- Lucas P. Quality checking of medical guidelines through logical abduction. Coenen F, Preece A, Mackintosh A, editors. In: Proceedings of AI-2003 (Research and Developments in Intelligent Systems XX). Springer. 2004; 309-321.
- CLSI (formerly NCCLS). Procedures for the Handling and Processing of Blood Specimens for Common Laboratory tests - Approved Guideline. 4th edition. Wayne: Clinical and Laboratory Standards Institute. 2010.
- Hong T, Hart K, Soh L-K, Samal A. Using spatial data support for reducing uncertainty in geospatial applications. GeoInformatica. 2014; 18: 63-92.
- Li R, Bhanu B, Ravishankar C, Kurth M, Ni J. Uncertain spatial data handling: modeling, indexing and query. Computers and Geosciences. 2007; 33:42-61.
- Schneider M. Uncertainty management for spatial data in databases: Fuzzy spatial data types. Güting RH, Papadias D, Lochovsky F, editors. In: Advances in Spatial Databases, Lecture Notes in Computer Science, 1651. Springer. 1999; 330-351.
- Freire L, Roche A, Mangin JF. What is the best similarity measure for motion correction in fMRI time series? IEEE Trans Med Imaging. 2002; 21: 470-484.
- Kakas A, Kowalski R, Toni F. The role of abduction in logic programming. Gabbay D, Hogger C, Robinson I, editors. In: Handbook of Logic in Artificial Intelligence and Logic Programming, 5. Oxford University Press. 1998; 235-324.
- Pereira LM, Anh HT. Evolution prospection. Nakamatsu K, Phillips-Wren G, Jain LC, Howlett RJ, editors. In: New Advances in Intelligent Decision Technologies: Results of the First KES International Symposium IDT, Studies in Computational Intelligence, 199. Springer. 2009; 51-63.
- Florkowski C. Sensitivity, Specificity, Receiver-Operating Characteristic (ROC) Curves and Likelihood Ratios: Communicating the Performance of Diagnostic Tests. Clin Biochem Rev. 2008; 29: 83-87.
- Hajian-Tilaki K. Receiver Operating Characteristic (ROC) Curve Analysis for Medical Diagnostic Test Evaluation. Caspian J Intern Med. 2013; 4: 627-635.
- World Health Organization: Obesity and overweight.
- Fernandes F, Vicente H, Abelha A, Machado J, Novais P, Neves J. Artificial Neural Networks in Diabetes Control. In: Proceedings of the 2015 Science and Information Conference. IEEE. 2015; 362-370.
- Vicente H, Dias S, Fernandes A, Abelha A, Machado J, Neves J. Prediction of the Quality of Public Water Supply using Artificial Neural Networks. J Water Supply Res T. 2012; 61: 446-459.
- Vicente H, Couto C, Machado J, Abelha A, Neves J. Prediction of Water Quality Parameters in a Reservoir using Artificial Neural Networks. Int J Des Nat Ecodyn. 2012; 7: 309-318.
- Vicente H, Roseiro J, Arteiro J, Neves J, Caldeira AT. Prediction of bioactive compound activity against wood contaminant fungi using artificial neural networks. Can J Forest Res. 2013; 43: 985-992.
- Mair J, Morandell D, Genser N, Lechleitner P, Dienstl F, Puschendorf B. Equivalent Early Sensitivities of Myoglobin, CK-MB Mass, CK Isoform Ratios and Cardiac Troponins I and T for AMI. Clin Chem. 1995; 41: 1266-1272.
- Larue C, Calzolari C, Bertinchant JP, Leclercq F, Grolleau R, Pau B. Cardiac-Specific Immunoenzymometric Assay of TnI in the Early Phase of AMI. Clin Chem. 1993; 39: 972-979.
- Keller T1, Zeller T, Peetz D, Tzikas S, Roth A, Czyz E, Bickel C. Sensitive troponin I assay in early diagnosis of acute myocardial infarction. N Engl J Med. 2009; 361: 868-877.