
Review Article
Ann Depress Anxiety. 2014;1(7): 1036.
Using a Person-Centered Methodology to Investigate the Co-Occurrence between Psychopathological Problems
Kostas A Fanti*
Department of Psychology, University of Cyprus, Cyprus
*Corresponding author: Kostas A Fanti, Department of Psychology, University of Cyprus, P.O. Box 20537, CY 1678, Nicosia, Cyprus
Received: October 23, 2014; Accepted: November 26, 2014; Published: November 28, 2014
Abstract
The present paper proposes that Latent Class Growth Analysis (LCGA) can be used for the identification of different groups of individuals exhibiting normative, pure or combined psychopathological problems. More specifically, LCGA allows for the identification of different subgroups of individuals who show homogeneous developmental trajectories of the behaviors under investigation, and provides the capacity for the joint estimation of trajectory models across the entire period of observation. LCGA can also aid in the identification of (1) possible factors that might place individuals at higher risk for exhibiting pure or combined psychopathology, and (2) developmental outcomes that might be related to higher risk groups of individuals. Studies using the LCGA method can offer a more comprehensive view of co-occurrence when compared to studies investigating point by point change or average trajectories of change over time. Findings on co-occurrence have the power to provide information on the validity of classification systems, etiological theories, and treatment.
Keywords: LCGA; Psychopathological problems; BIC; ANOVA
Introduction
One of the remaining major research challenges in psychology is the idea of co-occurrence [1,2]. Findings on co-occurrence are important because they can have implications for the validity of classification systems and treatment [1-5]. Furthermore, findings on factors related to co-occurrence can have implications for etiological theories, since risk factors associated with one disorder might in fact be risk factors for another disorder [2,3,6,7].
One of the main reasons behind the limited understanding of co-occurrence is the unavailability of appropriate analytic methods. Researchers have been using statistical methods, such as correlations, clinical cutoff scores, cluster analysis, and factor analysis, to identify syndromes that tend to co-occur in the individual; however these approaches are not built to take longitudinal change into account and at most these methods only test the association of two assessment periods [8]. The advent of latent growth models in Hierarchical Linear Modeling (HLM) and Structural Equation Modeling (SEM) enabled the estimation of the average trajectories of different behaviors, and the investigation of the co-development of different domains by relating their trajectories [9-12]. However, these models assume that individual curves within each behavior are relatively homogeneous and that growth trajectories in the model arise from a single multivariate normal distribution, which masks the presence of distinct subgroups.
According to Rutter and Sroufe [2], to investigate co-occurrence analytic methods need to be able to (1) take into account individual differences and possibly identify different classes of individuals exhibiting either pure or co-occurring psychopathology, (2) investigate both normative and pathological development to understand the link between them, (3) investigate the course of cooccurrence within a dynamic framework by taking trajectories of change into account, and (4) consider the origins and outcomes of cooccurrence. An analytic method that can take all of these components into account is a person oriented methodology known as Latent Class Growth Analysis [7,13], which is similar to the semi parametric group based trajectory approach proposed by Nagin [14].
LCGA allows for the identification of different subgroups of individuals who show homogeneous developmental trajectories of the target behavior [7,15,16]. Furthermore, the LCGA approach can relate the entire longitudinal course of two or more behaviors, and therefore provides the capacity for the joint estimation of trajectory models across the entire period of observation [7,8.13]. Hence, LCGA first identifies heterogeneous classes within each behavior of interest based on individuals’ distinct developmental courses and then joins these differential trajectories to determine which groups of individuals follow trajectories of normative, pure, or co-occurring psychopathological problems. After the identification of the different latent classes, possible factors that might place individuals at higher risk for exhibiting pure or combined psychopathological problems, and possible developmental outcomes that might be related to psychopathology can be included in the analyses [7].
Studies using the LCGA method can offer a more comprehensive view of co-occurrence when compared to studies investigating point by point change or average trajectories of change over time. LCGA enables the identification of heterogeneous developmental patterns of pure or combined psychopathological problems within a dynamic framework by taking trajectories of change into account, by investigating non-linear change, and by including all the available longitudinal data (even incomplete data) in the analysis. Additionally, while latent growth models assume that individual curves within each behavior are relatively homogeneous and that growth trajectories in the model arise from a single multivariate normal distribution, LCGA enables researchers to identify heterogeneous trajectories representing latent classes of individuals by modeling a mixture of distinct multivariate normal distributions [7,8,13,17]. Furthermore, based on the heterogeneous trajectories of each latent class and by taking longitudinal change into account, LCGA also estimates the joint occurrence among distinct latent classes of different behaviors, while latent growth models investigate the co-development of the average trajectories of change for each behavior. Finally, predictors and outcomes can be added in the analysis to compare groups of individuals exhibiting continues normative, pure, and co-occurring psychopathological problems.
Employing LCGA for the Investigation of Co-Occurrence
The next part of the paper aims to provide a description of how to use LCGA to investigate co-occurrence using the Mplus software [7,15]. In the first stage of the analyses, a single-latent growth model can be used to identify the average trajectories of psychopathological problems. In the second part of the analyses, LCGA can be used to identify distinct groups of individual trajectories separately for each problem behavior. The joint probabilities can be derived from a mixture model which includes the individual trajectories derived from the LCGA analysis. In the final stage, predictors and outcomes can be added in the analyses to identify characteristics that distinguish membership in the identified groups.
Average trajectories of psychopathological problems
A single-class latent growth model can be used to investigate the normative development of psychopathological problems. This type of growth model uses a polynomial function to model the relationship between the behavior under investigation and age [7,18]. The function takes the form
yιt= βo + β1Ageιt + β2Age2ιt + ε (1.1)
where yιt is a latent variable which characterizes the level of psychopathological problems for participant ι at time t. As seen in equation 1.1, the analysis is based on a quadratic growth curve. Investigators can decide which growth terms to include in their analysis based on the available times of measurement in their study. For example, if only three time points of measurement are available, only the intercept and the linear slope should be included in the equation. The unit of time in the equation is years of age; however grade or time of measurement can also be used as alternatives. Ageιt is participant ι’s age at time t, Age2 ιtis the square of participant ι’s age at time t, and ε is a disturbance assumed to be normally distributed. The model’s coefficients, βo, β1, and β2, determine the average shape of the trajectory. The single class growth analysis is demonstrated in Digure 1, with Time of measurement as the unit of analysis. The intercept indicates the average of each problem behavior at Time 1, and the linear and quadratic terms represent change over time.
Patterns of psychopathological problems over time
LCGA identifies heterogeneous classes by modeling a mixture of distinct multivariate normal distributions. Heterogeneity of trajectory classes is data-driven based on the estimation of individual growth curves for each participant. Individuals within each class are assumed to be homogeneous in respect to their developmental patterns. LCGA uses a polynomial function to model the relationship between an attribute and age [14,16,18,19]. The function takes the form [7,14]:
yιtj = βjo + βj1Ageιt + βj2Age2ιt + e (1.2)
where yιtjis a latent variable which characterizes the level of psychopathological problems for participant ιt at time t given membership in group j. Ageιt is participant ιt’s age at time t, Age2 ιt is the square of participant ιt’s age at time t, and e is a disturbance assumed to be normally distributed with zero mean and constant variance. The model’s coefficients, βj o, βj 1, and βj 2, determine the shape of the trajectory. The coefficients are superscripted by j to denote that they are not constrained to be the same across j groups and are free to vary, which allows for cross-group differences in the shape of developmental trajectories. Therefore, the absence of constraints captures mixtures of developmental trajectories in the population and also allows each group’s trajectory to have a distinct shape. Furthermore, the model does not permit individual variability in the intercepts or slopes within classes, and individuals within a class share a single trajectory of change over time. The LCGA model estimation in Mplus results in three outputs: (1) the shape of the trajectory for each class, (2) the un standardized and standardized values of each growth term for each class of individuals, and (3) the posterior probability of class membership. In addition, Mplus accommodates missing data by using full information maximum likelihood, retaining children with incomplete assessments in the analysis.
Model fit
The Lo, Mendel, Rubin (LMR) statistic and the Bayesian Information Criterion (BIC) can be used to compare models with different number of classes. Both of these model fit statistics should be used because they provide information about different aspects of model fit. The LMR statistic complements the BIC because the BIC tends to favor more parsimonious models compared to the LMR [19].
The BIC is usually used for LCGA models because it can be applied to nonnested models. The BIC, like all information criterion indices, is a goodness-of-fit measure that incorporates various penalties for model complexity, such as the number of parameters in the model [20-22]. The BIC is based on a maximization of a log likelihood function. If L is the maximized log likelihood, p is the number of free parameters in the model, and N is the number of cases, the BIC can be written as follows [22]:
BIC = -2 logL + p log(N), (2.1)
with a smaller value indicating a better fit [7]. The BIC does a good job in identifying the true model in large samples, but the BIC is biased in small samples by choosing models that are too simple [23].
In addition, because the BIC criterion tends to favor models with fewer classes by penalizing for the number of parameters [24], a likelihood statistic based on the sum of chi-square distributions should also be used. However, the usual likelihood ratio chi-square difference test can only be applied to compare nested models with the same number of classes, and therefore this type of test cannot be applied to mixture modeling with different number of classes [25,26]. Lo, Mendell, and Rubin adjusted the likelihood ratio test in order to be used in mixture modeling, to compare models with different number of classes, and to enable the comparison of non-nested models. Therefore, the Lo, Mendel, Rubin (LMR) fit statistic can be used to compare mixture models with different number of latent classes [25,26]. The LMR statistic tests k – 1 class against k classes, and it can be considered as a likelihood ratio test between models with different number of latent classes. A significant chi-square value (p < .05) indicates that the k – 1 class model has to be rejected in favor of the k-class model. A non-significant chi-square value (p > .05) suggests that a model with one fewer class is preferred. For example, in the case where 2- and 3-class models are compared, the null hypothesis states that a random sample was drawn from a mixture distribution with two classes, and the alternative hypothesis states that the sample has been drawn from a mixture distribution with 3-classes.
Furthermore, attention should be given to the shape and location of the different estimated class trajectories to indicate whether each latent class is distinct and whether the latent classes identified are meaningful. Nagin and Tremblay [8] indicated that the addition of a new class to the model might result in the splitting of a larger class into two smaller classes with similar trajectories, which is not informative. Therefore, when inspection of the graphs suggests that a model with more classes indicates the existence of similar classes of small theoretical importance, the model with fewer and distinct classes should be preferred.
Finally, the average posterior probabilities and the entropy value can be taken under consideration to indicate whether the classes in the final model are distinct [27]. Posterior probabilities determine the most likely latent class for each individual. The average posterior probabilities can be used to check for the precision of classification for each class of individuals, and therefore indicate the degree to which the classes are distinguishable. Average probabilities equal to or greater than .70 imply satisfactory fit [7,28]. In addition, the entropy value, which is a standardized summary measure based on the posterior class membership probabilities derived from each model, can be used to judge the classification accuracy of placing participants into classes and the degree of separation between classes [13,29]. Entropy can be represented as follows [29]:
EK = 1 –(Si SK –piK lnpiK) / n lnk (2.2)
where pik is the estimated conditional probability for individual i in class k, and n is the sample size. Entropy can range from zero to one, and a higher entropy value is preferred because it indicates clear classification and greater power to predict class membership. Moreover, entropy is a function of the number of classes, which suggest that a model with as many classes as observations would have an entropy value of one.
Joint probabilities
In the third part of the analysis, the groups identified with LCGA need to be entered in a joint mixture model in Mplus to investigate for joint probabilities between the two (or more) types of problem behaviors [7,13]. The joint analysis is based on the same principles as LCGA and assigns class membership in trajectory classes across behaviors taking into account longitudinal change over time. The inclusion of individuals in different combined classes is datadriven based on the estimation of individual growth curves for each participant. After identifying the latent classes based on the growth parameters for each problem behavior, the same growth terms should be used to combine the different classes and assign each individual in either a normative group, a co-occurring group or a group characterized as higher in one behavior and lower in the other [7,13]. For example, to specify a high risk co-occurring group, the intercept, linear and quadratic terms from the high risk group in one psychopathological problem, and the intercept, linear and quadratic terms from the high risk group in the other psychopathological problem should be combined to specify one joint class. The individuals who are at high risk on both psychopathological problems will be identified in the high co-occurring class. This procedure should be done for all the identified classes of each psychological problem. The Mplus guide provides a detailed explanation on how to write the syntax [15]. Figure 1 demonstrates how this approach works. As shown in the figure, this model uses all longitudinal measurements and links the two behaviors of interest across the entire period of observation. Furthermore, this type of procedure is preferred over simple crosstab analysis because it provides posterior probabilities and a value for entropy [8,13], which can be used to indicate whether the classes in the final model are distinct. Furthermore, the latent variables derived from LCGA have the potential to reduce measurement errors. The identified joint trajectories can be graphically displayed; representing distinct co-occurring groups [7].
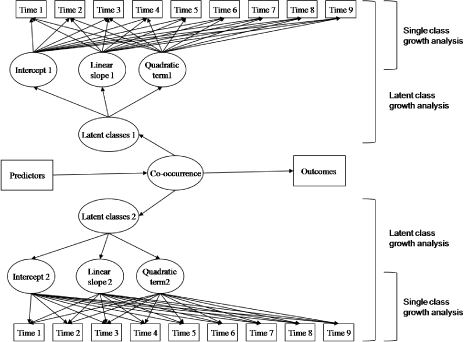
Figure 1: Schematic depiction of the joint Latent Class Growth Analysis model.
Identification of predictors and outcomes distinguishing group membership
After identifying the co-occurring classes, predictors and outcomes can be entered in the model, as shown in figure 1. Mplus allows for testing such complex models, which includes continuous and categorical observed variables and categorical longitudinal latent variables. Categorical and continuous variables can be used to predict the latent groups in the form of Multinomial Logistic Regression, and the different identified latent classes can be used to predict the different outcomes in the form of Analysis of Variance (ANOVA). Therefore, multinomial logistic regression analysis will be used by the Mplus program to identify predictors that discriminate among individuals with divergent pure or co-occurring developmental trajectories, and ANOVA analysis will be used to test whether there are statistically reliable mean differences among the trajectory groups. Since Mplus allows for the extraction of the identified groups in other statistical programs (with the use of the SAVEDATA function), these analyses can also be performed in other statistical environments, such as SPSS [7].
Finally, Mplus allows for the identified longitudinal latent classes to be used as a known latent categorical variable, which allows for the investigation of how membership in each class translates into longitudinal change for each measured variable. This type of multiple group mixture modeling is used when there is one latent categorical variable (i.e., different groups of individuals based on their scores on each psychopathological problem) for which class membership is known and equal to the latent groups identified in the sample. Therefore, this approach investigates how identified latent categorical groups in the sample change over time in terms of different developmental outcomes. An alternative approach could be the use of Repeated Measures ANOVAs (e.g., in SPSS), which will also allow for significance testing.
Conclusion
LCGA is an important tool to be used for the identification of different latent classes of individuals exhibiting pure or combined symptoms. In the case that high levels of co-occurrence between different disorders are detected may indicate that revisions of the taxonomy of constructs may be needed [1-3,5]. The definitions of individual psychopathological problems might be inappropriate, and definitions might need to also reflect different classes of distinct or combined problems [1-3]. Furthermore, co-occurring disorders have a higher cost to society compared to pure disorders [30-32]. Individuals exhibiting co-occurring disorders exceed individuals exhibiting pure disorders in terms of chronic history of mental illness, higher use of treatments, greater functional interference in daily life, more encounters with the justice system, unemployment, welfare dependence, and generally more impaired adaptation across domains such as work, education, health, and social-support networks [7,32]. Because of these reasons an understanding of co-occurrence is essential.
Additionally, studies using the method proposed in the current paper can provide findings on the developmental trajectories of different latent classes of individuals exhibiting normative, and pure or combined psychopathological problems, and how these differential latent classes are affected by different predictors and are expressed as negative developmental outcomes [7]. These findings may have the ability to inform the construction of intervention, prevention, and treatment programs for individuals exhibiting pure or cooccurring psychopathological problems. Findings can also suggests that interventions or treatments may need to be individually tailored to specific subgroups of individuals, since individuals exhibiting co-occurring problems may benefit from more comprehensive treatments compared to individuals with pure symptoms [3,7,33]. Even though multimodal treatments are expensive, the cost to the individual and to the society for not taking both symptoms into account may be far more expensive [32]. Furthermore, single-disorder interventions might not produce successful recovery to individuals with co-occurring disorders, although these interventions might be really important for individuals exhibiting pure psychopathological problems.
In conclusion, even though research has indicated the existence of pure and co-occurring forms of psychopathological problems, the evidence in the literature remain limited in many respects [6,7,34], and inefficient evidence on the issue of co-occurrence may lead to ineffective treatments because of the complex and diverse nature of co-occurring disorders [4,32]. Studies using the LCGA method can offer a more comprehensive view of co-occurrence when compared to studies investigating point by point change or average trajectories of change over time. More importantly, findings on co-occurrence have the power to provide information on the validity of classification systems, etiological and developmental theories, and treatment.
References
- Rutter M. Psychopathology: past scientific achievements and future challenges. Psychiatry: Past, Present, and Prospect. 2014; 219.
- Rutter M, Sroufe LA. Developmental psychopathology: concepts and challenges. Dev Psychopathol. 2000; 12: 265-296.
- Angold A, Costello EJ. Depressive comorbidity in children and adolescents: empirical, theoretical, and methodological issues. Am J Psychiatry. 1993; 150: 1779-1791.
- Keiley MK, Lofthouse N, Bates JE, Dodge KA, Pettit GS. Differential risks of covarying and pure components in mother and teacher reports of externalizing and internalizing behavior across ages 5 to 14. Journal of Abnormal Child Psychology. 2003; 31: 267-283.
- Lilienfeld SO. The Research Domain Criteria (RDoC): An analysis of methodological and conceptual challenges. Behav Res Ther. 2014.
- Fanti KA. Development and co-development of aggressive and depressive psychopathology: Infancy to early adolescence. Saarbruecken, Germany: VDM Verlag. 2008.
- Fanti KA, Henrich CC. Trajectories of pure and co-occurring internalizing and externalizing problems from age 2 to age 12: Findings from the National Institute of Child Health and Human Development Study of Early Child Care. Developmental Psychology. 2010; 46: 1159-1175.
- Nagin DS, Tremblay RE. Analyzing developmental trajectories of distinct but related behaviors: a group-based method. Psychol Methods. 2001; 6: 18-34.
- Brookmeyer KA, Fanti KA, Henrich CC. Schools, parents, and youth violence: a multilevel, ecological analysis. J Clin Child Adolesc Psychol. 2006; 35: 504-514.
- Bryk AS, Raudenbush SW. Hierarchical linear models: Applications and data analysis methods. Thousand Oaks, CA: Sage. 1992.
- Fanti KA, Panayiotou G, Fanti S. Associating parental to child psychological symptoms: Investigating a transactional model of development. Journal of Emotional and Behavioral Disorders. 2013; 21: 193-210.
- Willett JB, Sayer AG. Cross-domain analyses of change over time: Combining growth modeling and covariance structure analysis. Schumacker R, Marcoulides GA, editors. In: Advanced structural equation modeling techniques. Hillsdale, NJ: Erlbaum. 1996; 125-157.
- Muthen B. Latent Variable Mixrure Modeling. Marcoulides GA, Schumacker RE, editors. In: Advanced Structural Equation Modeling: New Developments and Techniques. Lawrence Erlbaum Associates. 2000; 1-33.
- Nagin DS. Analyzing developmental trajectories: A semiparametric, group-based approach. Psychological Methods. 1999; 4: 139-157.
- Muthen LK, Muthen BO. Mplus: Statistical analysis with latent variables: User's guide. Los Angeles, CA: Muthén & Muthen. 2010.
- Nagin D, Tremblay RE. Trajectories of boys' physical aggression, opposition, and hyperactivity on the path to physically violent and nonviolent juvenile delinquency. Child Dev. 1999; 70: 1181-1196.
- Nylund KL, Asparouhov T, Muthen BO. Deciding on the number of classes in latent class analsysis and growth mixture modeling: A Monte Carlo simulation study. Structural Equation Modeling: A Multidisciplinary Journal. 2007; 14: 535-569.
- Muthen B. Second-generation structural equation modeling with a combination of categorical and continuous latent variables: New opportunities for latent class-latent growth modeling. L. M. Collins & A. G. Sayers (Eds.) In, new methods for the analysis of change. Washington, DC: American Psychological Association. 2001; 291-322.
- Kreuter F, Muthen B. Analyzing criminal trajectory profiles: Bridging multilevel and group-based approaches using growth mixture modeling. Submitted for publication. 2008.
- D’Unger A, Land K, McCall P, Nagin D. How many latent classes of delinquent/criminal careers? Results from mixed Poisson regression analyses of the London, Philadelphia, and Racine cohort studies. American Journal of Sociology. 1998; 103: 1593-1630.
- Kass RE, Raftery AE. Bayes factors. Journal of the American Statistical Association. 1993; 90: 773-795.
- Schwartz. Estimating the dimension of a model. The Annals of Statistics. 1978; 6: 461-464.
- Barron AR, Cover TM. Minimum complexity density estimation. IEEE Theory. 1991; 37: 1034–1054.
- Bauer DJ, Curran PJ. Distributional assumptions of growth mixture models: implications for overextraction of latent trajectory classes. Psychol Methods. 2003; 8: 338-363.
- Lo Y, Mendell N, Rubin DB. Testing the number of components in a normal mixture, Biometrika. 2001; 88: 767-778.
- Muthén B. Statistical and substantive checking in growth mixture modeling: comment on Bauer and Curran. Psychol Methods. 2003; 8: 369-377.
- Jedidi K, Jagpal HS, DeSarbo WS. Finite-mixture structural equation models for response-based segmentation and unobserved heterogeneity. Marketing Science. 1997; 16: 39- 59.
- Nagin DS. Group based modeling of development. Campridge, MA: Harvard University press. 2005.
- Ramaswamy V, Desarbo W, Reibstein D, Robinson W. An empirical pooling approach for estimating marketing mix elasticities with PIMS data. Marketing Science. 1993; 12: 103-124.
- Cohen MA. The monetary value of saving a high-risk youth. Journal of Quantitative Criminology. 1998; 14: 5-33.
- Foster EM, Dodge KA, Jones D. Issues in the Economic Evaluation of Prevention Programs. Appl Dev Sci. 2003; 7: 76-86.
- Newman DL, Moffitt TE, Caspi A, Silva PA. Comorbid mental disorders: implications for treatment and sample selection. J Abnorm Psychol. 1998; 107: 305-311.
- Russo M, Beidel D. Comorbidity of childhood anxiety and externalizing disorders: Prevalence, associated characteristics, and validation issues. Clinical Psychology Review. 1994; 14: 199-221.
- Oland AA, Shaw DS. Pure versus co-occurring externalizing and internalizing symptoms in children: The potential role of socio-developmental milestones. Clinical Child and Family Psychology Review. 2005; 8: 247-270.